Requisitos: A Base que Esquecemos na Pressa de Entregar Código
Um guia prático sobre análise de requisitos, metodologia Shape Up e como implementar documentação efetiva no dia a dia de desenvolvimento.
Resolvi voltar a estudar as bases que aprendi na faculdade, que pela correria do dia a dia eu deixei de lado. A primeira delas, talvez a mais importante, é a parte de REQUISITOS. Tive uma professora excelente na faculdade que ensinou realmente tudo que eu precisava saber sobre documentação de projeto. Porém, como a maioria (creio eu), eu acabei focando em programar, programar, programar, e nessas matérias de documentação eu só aprendia o necessário para passar. Ainda bem que ela nos "forçou" e incentivou a aprender isso, porque com toda certeza é uma das melhores coisas que aprendi como dev.
Resolvi começar a estudar a parte de documentação pela análise de requisitos, por meio do curso Engenharia de Requisitos para Devs do DEV+EFICIENTE vendo os requisitos funcionais e não funcionais, processos para definir e tudo mais. Revendo o conteúdo, decidi fazer um pequeno resumo de forma prática, mostrando como vou começar a implementar isso no meu dia a dia de trabalho como desenvolvedor.
Um dos novos métodos que vi foi o Shape Up, que se propõe a ser um meio termo entre Waterfall e Scrum. Não existe método perfeito, cada um tem seu lugar de ser usado dependendo de N aspectos, mas o importante de entendê-los é que, mesmo que não usemos no dia a dia, podemos tirar insights valiosos deles.
Ele possui 3 fases: Shaping, Betting e Building.
Shaping É aquele momento de moldar a ideia, mas sem entrar em detalhes absurdos. Você pega uma oportunidade de negócio ou um problema, define os limites do que faz sentido desenvolver e desenhar uma solução que é tangível, mas ainda com espaço para o time descobrir os detalhes durante a execução. É tipo "vamos construir algo assim, mais ou menos nesse tamanho, com esse objetivo claro". Não é um PRD de 50 páginas, é mais um rascunho que dá direção.
Betting É quando as pessoas que têm poder de decisão (geralmente a liderança de produto e negócios) olham para as ideias "shapadas" e decidem: "vamos apostar nessa aqui". É um momento de priorização dura, onde você compara várias oportunidades e aposta tempo do time (seis semanas, normalmente) em algo que vai gerar resultado. O legal é que, se não for priorizado, não fica no limbo, a ideia some da fila e volta só se for reshaped.
Building É a execução propriamente dita, onde o time pega o shape, tem autonomia para transformar aquilo em software funcionando, dentro do tempo da aposta. A diferença pro Scrum é que você não tem retrospectiva toda semana nem reuniões de status, o time foca 100% na entrega, e só no final se avalia o que aprendeu.
Podemos mesclar isso com o Scrum que é a metodologia que trabalho hoje na minha empresa. O mais importante é termos claro o que são requisitos funcionais e não funcionais.
Requisitos funcionais são input e output, algo que se eu sei que o sistema deve fazer: se entrar X, o sistema tem que fazer Y e sair Z.
Requisitos não funcionais são restrições do sistema, atributos de qualidade do sistema: uptime de 99,5%, aguentar 500 mil requisições por mês.
Tendo isso claro, vamos aos passos de como definimos isso. O mais importante de todos e o mais difícil: normalmente o desenvolvedor não está na fase de que o pessoal de produto define o projeto ou a nova feature, porém precisamos ter acesso a quem pediu para entendermos se o que nos foram pedidos está correto, se entendemos certo, e até mesmo entendermos se ele realmente quer isso ou se ele só não soube explicar o que quer.
Então, primeiro, antes mesmo de começar a arquitetar o sistema, precisamos conversar com quem pediu. Não é "reunião de levantamento de requisitos" formal, é literalmente: "Me chama pra call de 15 min, vamos marcar um papo com quem teve a ideia". É nesse papo que a gente tira a maior parte da sujeira.
Análise da Causa Raiz, os "5 Porquês" Não dá pra simplesmente aceitar "preciso de um dashboard". Por quê? "Porque os clientes estão cancelando". Por quê? "Porque demora muito pra conseguir suporte". Por quê? "Porque não sabemos qual cliente precisa de atenção urgente". Por quê? "Porque nosso sistema não prioriza tickets". Por quê? "Porque não temos visão de impacto no cliente".
Aí você vê: o problema não é "dashboard". É "identificar clientes de alto impacto que precisam de suporte urgente". Esse nível de clareza muda completamente o que você vai construir.
Double Check e Triple Check: Não Assuma Nada Depois da conversa inicial, você vai ter um entendimento. Ótimo. Agora você materializa isso de volta para quem pediu e pergunta: "É isso mesmo?" (Double Check). E depois de ajustar, mostra de novo: "Agora entendi direito?" (Triple Check).
É simples, mas evita que você vá para o caminho errado. Só passa pra próxima quando a pessoa responder "Isso!".
Breadboarding: Desenhe o Fluxo Antes do Código Breadboarding é um negócio do Shape Up que eu adorei: antes de codar, você pega um quadro branco (ou Figma, Excalidraw, até bloco de notas) e desenha a experiência do usuário passo a passo. Não é wireframe bonitinho, é rascunho feio mesmo: caixa, seta, caixa, seta.
O segredo é materializar o fluxo e identificar onde tem incerteza. Você vê exatamente onde o usuário entra, onde tem decisão, onde tem integração. E quando mostra isso para quem pediu, as falhas de lógica aparecem na hora.
Crie Cenários de Teste ANTES de Começar a Codar Isso muda tudo. Depois que você tem o entendimento e o breadboard, escreva os cenários de teste em Gherkin ou até em lista simples. Não é para testar depois que construir, é para validar se você realmente entendeu o comportamento esperado. Se você não consegue escrever um cenário de teste claro, você não entendeu o requisito.
Descreva as Implementações: Histórias, Critérios, Stakeholders Só depois de tudo isso você vai para a parte "bonitinha" das histórias, critérios de aceite, quem são os stakeholders, quem é o responsável pela feature. Se fizer isso antes, você vai estar documentando suposição, não entendimento validado.
Exemplo Prático com IA: Sistema de Análise Automática de PRs
Vamos pegar um exemplo de algo que envolve IA, já que é o assunto do momento. A ideia: um sistema que analisa Pull Requests automaticamente e dá sugestões de melhoria de código, identifica bugs e avalia qualidade.
Descrição Inicial (O que me pediram)
"Queremos uma IA que analise nossos PRs automaticamente e diga se tem problema, pra agilizar nossa revisão."
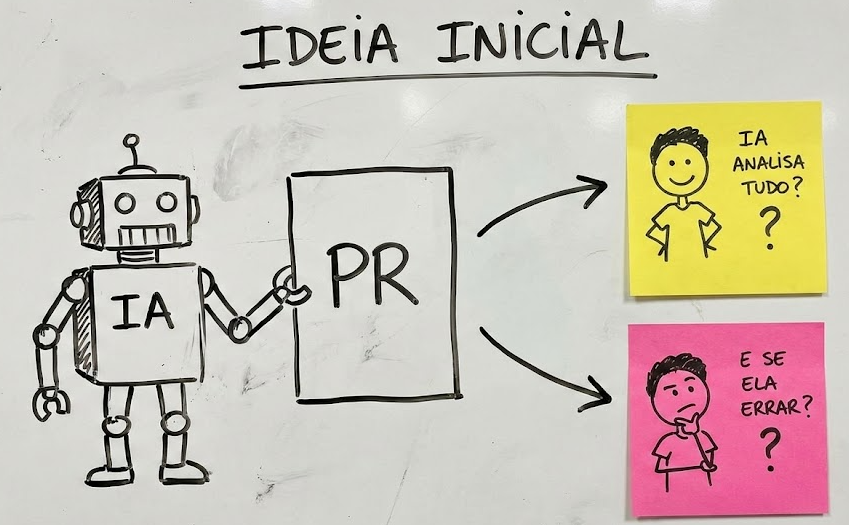
Quem pediu ou é responsável por essa ideia?
- PM de Produto Interno: Ana Souza
- Tech Lead: Carlos Mendes
- Motivação: Time de 15 devs, fila de PRs demora 2 dias em média, muitos comentários de revisão são sobre coisas repetitivas (formatação, variáveis não usadas, etc.).
Análise da Causa Raiz (5 Porquês)
- Por que precisamos IA nos PRs? Porque revisão manual está lenta.
- Por que está lenta? Porque os revisores estão marcando problemas triviais que poderiam ser automatizados.
- Por que estão marcando manualmente? Porque não temos ferramentas de lint/análise estática que cobrem nossos padrões específicos.
- Por que não temos? Porque nossos padrões estão documentados, mas não são "codificáveis" em regras simples.
- Por que não são codificáveis? Porque envolvem contexto de negócio (ex: "não use funções síncronas em endpoints de pagamento").
Conclusão: O problema não é "IA nos PRs". É "automatizar a identificação de violações de padrões que requerem contexto".
Descrição Detalhada do Entendimento
Requisito: Sistema de Análise Inteligente de Pull Requests
Objetivo
Reduzir o tempo de revisão manual de PRs em 40% automatizando a detecção de violações de padrões de código que requerem contexto de negócio.
Requisitos Funcionais
1. Análise de Código por Contexto
O sistema deve analisar o diff do PR e identificar violações de padrões específicos do negócio:
- Padrão de Pagamento: Nenhuma função síncrona em arquivos `/routes/payment/*.ts`
- Padrão de Segurança: Chaves de API não devem aparecer em logs, mesmo em comentários
- Padrão de Performance: Queries SQL devem ter índices documentados em comentários
- Padrão de Testes: TODOs em código devem ter issue vinculada (formato `TODO-123`)
2. Classificação de Severidade
Para cada violação encontrada, a IA deve classificar:
- CRÍTICA: Bug de produção provável (bloqueia merge)
- ALTA: Violação clara de padrão (sugere bloqueio)
- MÉDIA: Recomendação de melhoria (aviso, não bloqueia)
- BAIXA: Refatoração opcional (informacional apenas)
3. Aprendizado com Feedbacks
O sistema deve permitir que desenvolvedores marquem uma sugestão da IA como:
- Correta: Aplica automaticamente fix
- Falsa positiva: IA aprende e não repete
- Ignorada: Desenvolvedor ignorou, mas IA continua sugerindo
4. Integração com GitHub
- Deve funcionar como GitHub App, recebendo webhooks de PR abertos/atualizados
- Deve postar comentários inline no código
- Deve atualizar status de check (pass/fail) no PR
- Deve funcionar com PRs de forks (segurança)
Requisitos Não Funcionais
- Latência: Análise deve completar em < 30 segundos para PRs de até 500 linhas
- Precisão: Taxa de falsos positivos < 15% após 100 PRs treinados
- Disponibilidade: 99% de uptime (não pode bloquear pipeline de CI)
- Segurança: Nunca enviar código para serviços de IA externos, tudo local via Ollama/Llama.cpp
- Escalabilidade: Deve suportar 50 PRs simultâneos sem degradação
Fluxo de Dados

Cenários de Teste
Funcionalidade: Análise de PR com violação crítica
Cenário: IA detecta função síncrona em endpoint de pagamento
Dado um PR com arquivo "/routes/payment/credit-card.ts" contendo "app.post('/process', async (req, res) \=\> { const result \= syncProcess(); })"
Quando o sistema analisar o PR
Então deve ser adicionado comentário inline: "VIOLAÇÃO CRÍTICA: Função syncProcess() não permitida em rotas de pagamento"
E o status check deve ser "fail"
Cenário: Feedbacks melhoram precisão
Dado que a IA marcou um comentário como "falta de índice"
E 3 devs marcaram como "falsa positiva"
Quando um novo PR com situação similar for analisado
Então a IA não deve mais sugerir essa mesma alteração
Cenário: PR pequeno é analisado em menos de 30s
Dado um PR com 50 linhas de diff
Quando o webhook for disparado
Então a análise deve completar em no máximo 30 segundos
Nosso Entendimento foi Validado?
Sim. Ana validou o fluxo e confirmou que a preocupação principal era não bloquear merges indevidamente. Carlos validou que modelo local é mandatório por segurança.
Rascunhos que Materializam Nosso Entendimento
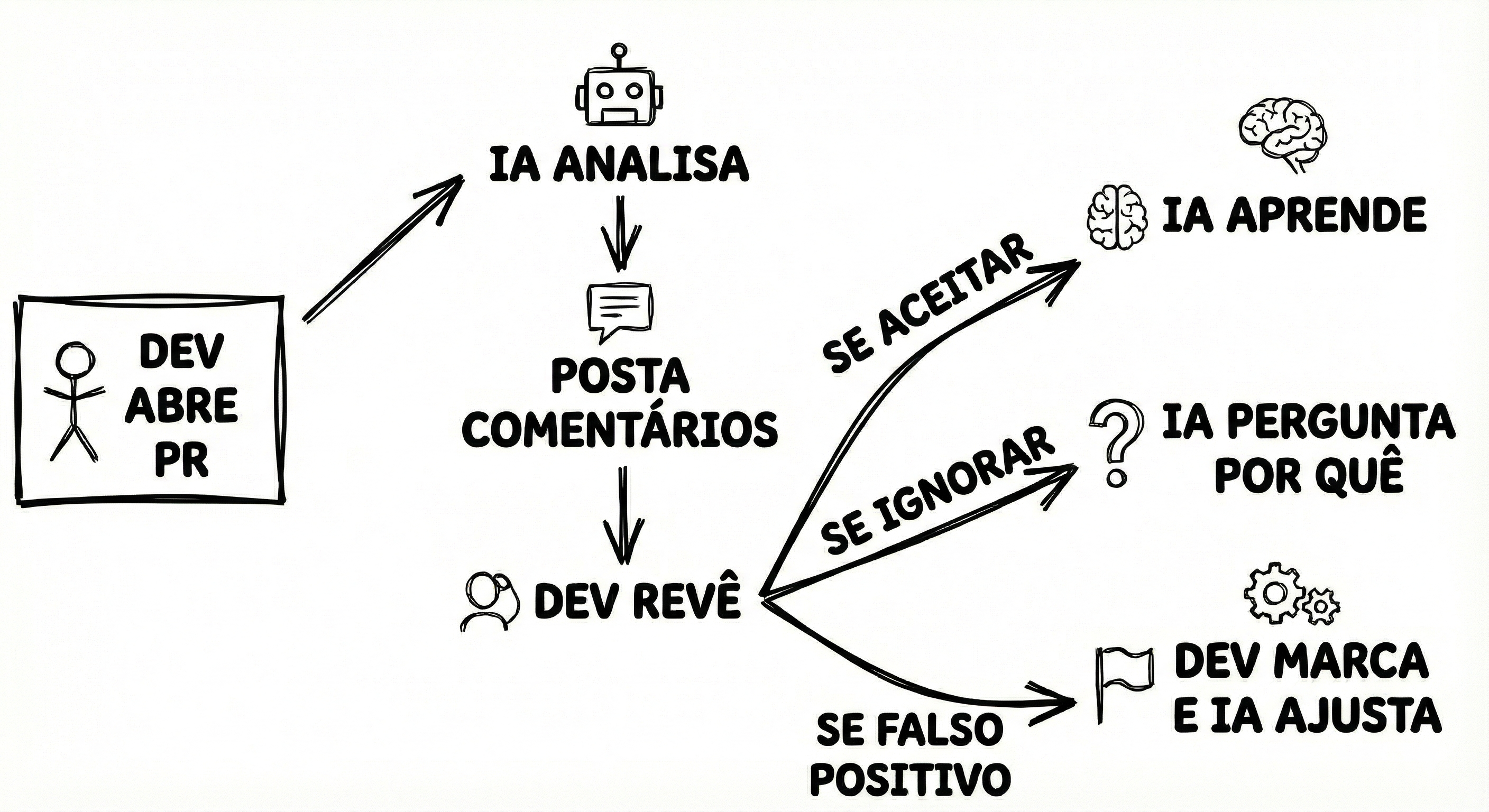
Os Rascunhos foram Validados?
Sim. Time inteiro revisou em reunião de 30 min. Identificamos que precisamos de um "modo silencioso" para os primeiros 10 PRs (só observar, não comentar).
Especificações dos Cenários de Testes
Além dos cenários acima, vamos validar:
- IA com 0 feedbacks: Deve ter taxa de acerto base de pelo menos 60%
- IA com 50 feedbacks: Deve alcançar 85% de acerto
- Cenário de erro: Se modelo LLM falhar, sistema deve retornar status de check "neutral" e logar erro
- Segurança: Tentativa de PR malicioso com código que tenta extrair o modelo → deve ser bloqueado
Histórias/Tarefas Derivadas
- Setup inicial: GitHub App, webhooks, infraestrutura Ollama (3 story points)
- Analisador de padrões: Engine que lê diff e aplica regras de contexto (5 story points)
- Integração LLM: Prompt engineering, tuning do modelo (8 story points)
- Sistema de feedback: UI no GitHub para marcar corretude das sugestões (3 story points)
- Modo silencioso: Feature flag para rodar sem postar comentários (2 story points)
Próximos Passos
- Semana 1: Setup do ambiente e primeiro PR analisado manualmente
- Semana 2: Integração com LLM local rodando
- Semana 3: Primeira versão postando comentários em 1 repositório de teste
- Semana 4: Coleta de feedbacks e ajuste de precisão